《表3 模型训练结果:软件开发活动数据集的层次化、多版本化方法》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
其次,基于2013年的数据集进行模型的训练、测试及调整.我们选取了数据集中最近5年,即2008年1月1日(北京时间,下同)后得到解决的(有Solution的)问题报告.此外,问题的最终解决需要经过一段时间的验证,即发现Solution的错误并纠正,因此,数据集中最后一段时间的问题报告的Solution有相对较高的不稳定性,无法准确地判断其是否是重复问题报告.我们对关于DUPLICATE的Solution错误出现的频率及其纠正时间进行了统计,发现有约2%的报告存在这样的错误,其中超过75%的报告在1年内得到了纠正.因此,我们过滤掉其中最后一年的问题报告,即保留2008年1月1日~2012年1月1日之间提交的问题报告,保证其中不准确报告的数量小于0.5%(2%? (1-75%))(由于部分错误的纠正需要10年以上的时间,为了保证有足够的数据,本文以损失1年的数据为代价使不准确的报告数量控制在0.5%以内).对剩余报告,我们按照其被提交的先后顺序选取了前80%作为训练数据,而后20%作为测试数据.训练结果见表3,可以看到,NR的系数显著不为0,其解释度为2.9%这说明,该模型具备判定能力,满足本示例的需求.
| 图表编号 | XD0073049700 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.07.01 |
| 作者 | 朱家鑫、周明辉 |
| 绘制单位 | 北京大学信息科学技术学院软件研究所、高可信软件技术教育部重点实验室(北京大学)、中国科学院软件研究所软件工程技术研究开发中心、北京大学信息科学技术学院软件研究所、高可信软件技术教育部重点实验室(北京大学) |
| 更多格式 | 高清、无水印(增值服务) |
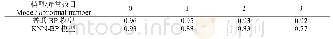




{kind=link}