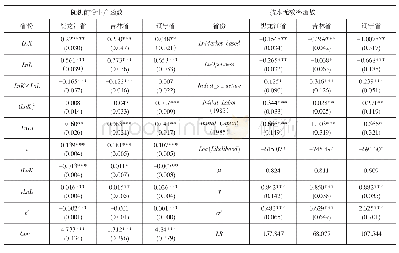
《表2 不同规模生猪养殖随机前沿生产函数的估计》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
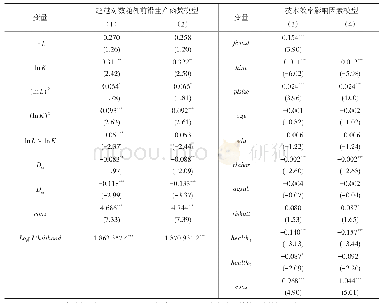
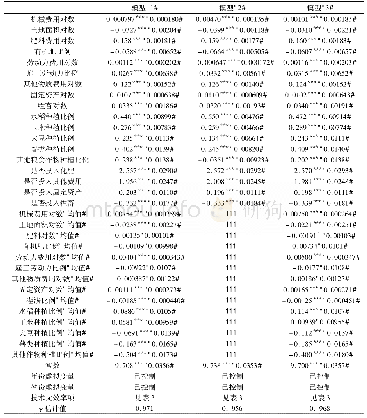
注:*、**、***分别表示在10%、5%和1%的水平下显著。
利用stata12软件对不同规模生猪养殖的随机前沿生产函数进行了估计,结果见表2。总体来看,模型1—3中的Usigma(非效率项)和Vsigma(随机误差项)的估计系数均在1%的水平上显著,说明我国不同规模生猪养殖中同时存在技术非效率和随机误差,因此选择随机前沿生产函数模型进行实证分析是合理的。此外,为了检验生产函数形式是否可以由Trans-log形式简化为C-D形式,我们对模型1—3中二次项和交叉项的估计系数分别进行了联合显著性检验,结果均在1%的水平上拒绝了二次项和交叉项估计系数显著为0的原假设,说明将生产函数形式设定为Translog形式是合理的。
| 图表编号 | XD0071739300 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.05.01 |
| 作者 | 王善高、田旭、张晓恒 |
| 绘制单位 | 南京农业大学经济管理学院、南京农业大学经济管理学院、华中农业大学经济管理学院 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}