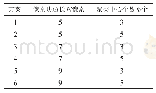
《表1 实验超参数设置:基于主述位理论的汉语基本篇章单元识别》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
实验选用的语料为苏州大学自然语言处理实验室构建的基于微观话题结构(Micro-Topic Scheme)的汉语篇章话题结构语料库(Chinese Discourse Topic Corpus,CDTC)。汉语篇章话题结构语料库从CTB 6.0中抽取了500篇文档进行语料标注,采用微观话题结构标注体系。该语料中所有识别项目的Kappa值均大于0.75,其中基本篇章单元识别的Kappa值为0.91,主述位识别的Kappa值为0.83。实验超参数设置如表1所示。
| 图表编号 | XD0070612100 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.08.01 |
| 作者 | 葛海柱、孔芳、周国栋 |
| 绘制单位 | 苏州大学计算机科学与技术学院、苏州大学计算机科学与技术学院、苏州大学计算机科学与技术学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}