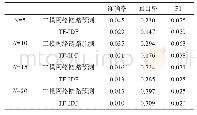
《表4 实验结果:基于门控记忆网络的汉语篇章主次关系识别方法》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
为了检验本文方法GMN-Nu的性能,设置了两个基准系统:(1)最好的传统模型ME[17],该模型使用语义相似度、上下文特征,采用最大熵模型;(2)最好的神经网络模型TMN[18],使用Bi-LSTM和CNN对两个篇章单元编码后使用三种匹配关系:Cosine、Bilinear和Single Layer Network,分别用于计算语义相似度、线性关系和非线性关系,最后用于篇章主次关系识别。表4展示了使用词向量作为输入的GMN-Nu模型与ME和TMN性能比较。
| 图表编号 | XD0054901300 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.05.01 |
| 作者 | 王体爽、李培峰、朱巧明 |
| 绘制单位 | 苏州大学计算机科学与技术学院、苏州大学计算机科学与技术学院、苏州大学计算机科学与技术学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}