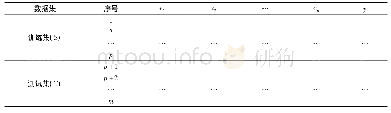
《表4 训练集与测试集的数据划分》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
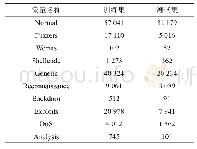
本研究以R语言实现随机森林算法建模过程,建立梅河大米产地确证模型。为保证数据划分的随机性和一致性,运用sampling包中的strata()函数实现分层抽样,将原始数据集的166个样本以7∶3的比例划分为训练集和测试集,保证来自于梅河及相邻产区的大米样本比例一致,训练集样本116个用于模型的建立和优化,测试集样本50个用于外部精度检验,数据分布见表4。
| 图表编号 | XD0067128200 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.06.01 |
| 作者 | 王靖会、吴玥、臧妍宇、陈云志、王艳辉、闵伟红 |
| 绘制单位 | 吉林农业大学信息技术学院、吉林农业大学信息技术学院、吉林农业大学信息技术学院、吉林省食品检验所、长春市净月高新技术产业开发区永兴街道办事处、吉林农业大学食品科学与工程学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}