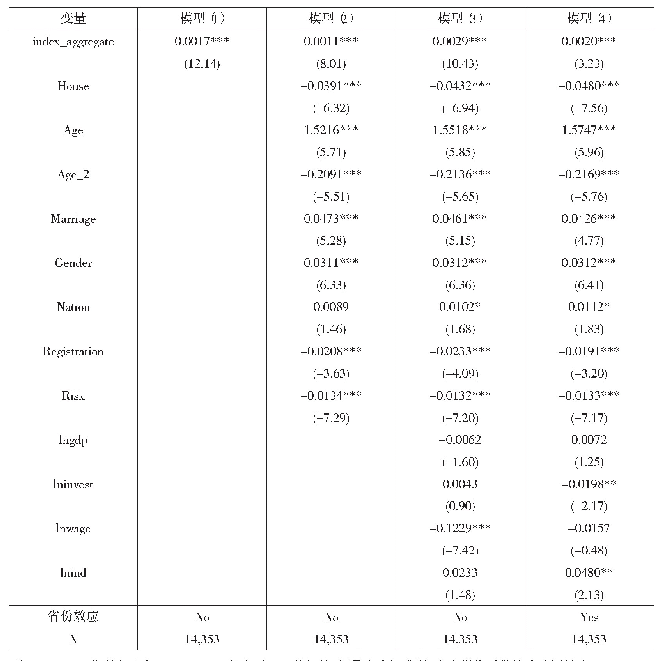
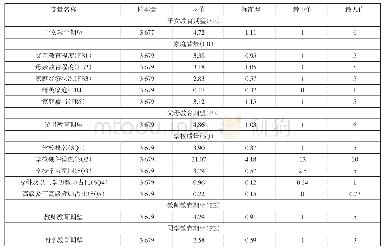
《表2 回归统计结果:收入识别与长期多维贫困:基于中国家庭追踪调查数据的实证分析》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《收入识别与长期多维贫困:基于中国家庭追踪调查数据的实证分析》
注:括号内为标准误,*、**和***分别表示显著性水平为10%、5%和1%。
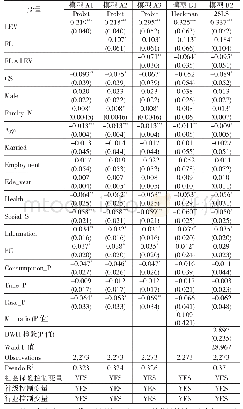
随机效应模型的回归结果如表2所示,在微观层面,受教育程度与工作变量在5%的水平下均显著,但在随机效应部分,受教育程度与工作变量在两类人群(收入是否低于低保线)之间的随机系数不显著,说明两类人群在决定收入的这两个关键变量上的差异很小。但同时两个变量所代表的收入维度识别却对居民能否获得低保的影响显著,这也表明以收入作为单一识别标准时贫困瞄准精确度较低,需要考虑引入更多维度的贫困识别指标。由表2可知,模型截距项的随机效应在1%的水平下显著,因此在构建完整模型时需要在截距项中继续纳入宏观变量来解释其截距系数,而不需将受教育程度和工作比例的斜率作为因变量来构建第二层方程。
| 图表编号 | XD0066945900 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.08.15 |
| 作者 | 胡继亮、张天祐、辛晓晨、肖庆兰 |
| 绘制单位 | 华中师范大学经济与工商管理学院、华中师范大学经济与工商管理学院、华中师范大学经济与工商管理学院、华中师范大学经济与工商管理学院 |
| 更多格式 | 高清、无水印(增值服务) |

{kind=link}