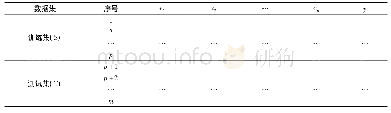
《表3 训练集和测试集的设置方案》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
我们切割的各类声音片段的总数如表1所示,分别为46 517,25 357,12 966,按八二比例将它们分为训练集和测试集.划分有3种方案,如表3(见第534页)所示.第1种保持八二比例的原始数据,显然鼾声、呼吸声和其他噪声片段的数量相差较大,鼾声片段的数量远远大于呼吸声和其他噪声片段的数量.针对这种类别数据不平衡的问题,第2种方案是直接对训练集里的多数类别的样本进行下采样(downsampling),即去除多数类别中多余的样本量,使得各类样本的数量接近.第3种方案是对训练集中的少数类别的样本进行上采样(upsampling),即增加一些少数样本的数量,使得各类样本的数量接近.第3种方案对于训练集中样本数量较少的呼吸声和其他噪声片段,通过加入白噪声的方式,合成新的信噪比为20dB的“呼吸声”和“其他噪声”加入训练集的对应类别中,使得训练集的呼吸声与其他噪声片段同鼾声片段的数量一样.3个方案中测试集相同.本文分别对训练集进行下采样和上采样处理以解决类别不平衡问题.详细数据见表3.
| 图表编号 | XD0057729100 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.08.01 |
| 作者 | 侯丽敏、刘焕成、施晓宇、张新鹏 |
| 绘制单位 | 上海大学通信与信息工程学院、上海大学通信与信息工程学院、上海大学通信与信息工程学院、上海大学通信与信息工程学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}