《表8 不同文本特征的对比实验结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
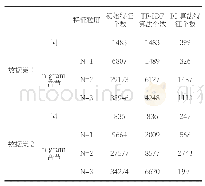
最后比较不同文本特征提取方式对模型性能的影响,分别采用直接独热编码的词袋模型、TF-IDF、基于维基百科语料训练的分布式词向量、基于故障现象小样本语料训练的分布式词向量和本文提出的字向量特征,并使用同一参数的随机森林模型进行预测,观察效果.实验结果见表8.从结果中可以看到,直接使用词袋模型的独热编码方式由于无法提取文本特征的上下文特征和领域特征,效果最差;而TF-IDF,Word2Vec+维基百科语料的准确度比较接近;而Word2Vec+故障现象语料的准确度也较差,这是因为故障现象语料较少,直接使用上下文关系预测词向量的方式效果较差;而采用卷积神经网络提取基于字符级的字向量特征的方法比其他方法在总体性能上更好,平均各项指标比Word2Vec+维基百科语料要高0.03,从而可以说明采用卷积神经网络的文本特征提取方式对文本特征提取更加充分,更能反映与故障原因的关系.
| 图表编号 | XD0056210200 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.05.01 |
| 作者 | 王锐光、吴际、刘超、杨海燕 |
| 绘制单位 | 北京航空航天大学计算机学院、北京航空航天大学计算机学院、北京航空航天大学计算机学院、北京航空航天大学计算机学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}