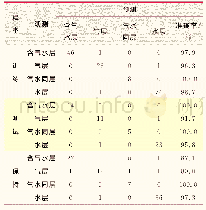
《表3 施氮样本分类训练结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
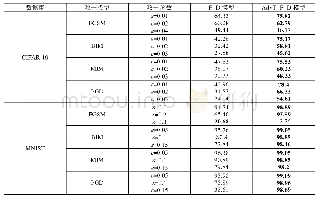
根据上述分析结果,在训练样本中排除极端的无氮样本,对其余混合样本进行K-means聚类,建立具有代表性的混合样本集用于分类器训练。根据训练结果(表3),综合考虑总体分类准确率和穗部分类准确率,选择wei KNN分类器用于识别麦穗,对麦穗识别结果进行自动穗数统计(图8)。与直接混合所有氮水平的统计结果(图7-e)相比,统计效果明显改善,计数准确率由84.6%提高到了92.9%,穗数统计值与实测值相关性也有明显改善,R2由0.15提高到了0.71。因此,在施氮区域可以忽略氮水平差异进行的麦穗识别统计,统计结果较为可靠。
| 图表编号 | XD0048684900 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.01.01 |
| 作者 | 杜颖、蔡义承、谭昌伟、李振海、杨贵军、冯海宽、韩东 |
| 绘制单位 | 江苏省粮食作物现代产业技术协同创新中心、江苏省作物遗传生理国家重点实验室培育点、教育部农业与农产品安全国际合作联合实验室、扬州大学农业科技发展研究院、农业部农业遥感机理与定量遥感重点实验室、北京农业信息技术研究中心、江苏省粮食作物现代产业技术协同创新中心、江苏省作物遗传生理国家重点实验室培育点、教育部农业与农产品安全国际合作联合实验室、扬州大学农业科技发展研究院、江苏省粮食作物现代产业技术协同创新中心、江苏省作物遗传生理国家重点实验室培育点、教育部农业与农产品安全国际合作联合实验室、扬州大学农业科技发展研 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}