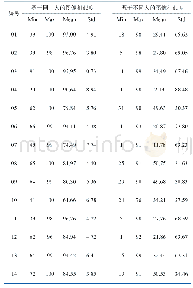
《表3 同一人和不同人人脸图像相似度的数据统计》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
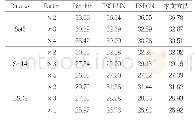
图4中还可以看到,由于不同人的相似度数据量(9.9999×109)较大,不同人的相似度分布曲线较为流畅,相似度的取样间隔适中,实验的可重复性较好,能够基本反映实验数据要求下不同人人脸图像相似度分布的统计特性。而相同人的相似度数据量(105)较小,算法4、算法5、算法9、算法13的结果中数据噪声较为明显。很多文献在计算相似度分布时,由于实验样本数量的限制,假设服从正态分布,但根据本实验中测试数据在显著性水平为0.05时,对所有14个算法的同一人相似度分布和不同人相似度分布进行单样本正态分布Lilliefors检验,结果见表2,H为接受或拒绝正态分布假设(1为拒绝,0为接受),P为接受假设的概率值(小概率时对原假设提出质疑),LSTAT为测试统计量的值,CV为是否拒绝原假设的临界值。实验结果显示:对所有的算法源于同一人图像和源于不同人图像两个测试中,正态分布拟合优度测试统计量(LSTAT)均大于临界值,因而拒绝正态分布假设。表3给出实验结果中同一人和不同人人脸图像的相似度的最小值(Min)、最大值(Max)、平均值(Mean)、标准差数据(Std)。由于不能使用正态分布的假设,这里不再给出参考阈值和置信区间,以免误导读者对于相似度数据的判断。
| 图表编号 | XD0044893300 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.02.15 |
| 作者 | 黎智辉、谢兰迟、王桂强、王海欧、牛勇、许磊、晏于文、李志刚、许小京、黄威、张宁、郭晶晶、侯欣雨 |
| 绘制单位 | 公安部物证鉴定中心现场物证溯源技术国家工程实验室、公安部物证鉴定中心现场物证溯源技术国家工程实验室、公安部物证鉴定中心现场物证溯源技术国家工程实验室、公安部刑事侦查局、公安部刑事侦查局、公安部物证鉴定中心现场物证溯源技术国家工程实验室、公安部物证鉴定中心现场物证溯源技术国家工程实验室、公安部物证鉴定中心现场物证溯源技术国家工程实验室、公安部物证鉴定中心现场物证溯源技术国家工程实验室、公安部物证鉴定中心现场物证溯源技术国家工程实验室、公安部物证鉴定中心现场物证溯源技术国家工程实验室、公安部物证鉴定中心现场物 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}