《表3 资源数据模型:画像分析为基础的图书馆大数据实践——以国家图书馆大数据项目为例》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《画像分析为基础的图书馆大数据实践——以国家图书馆大数据项目为例》
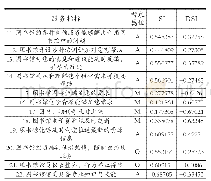
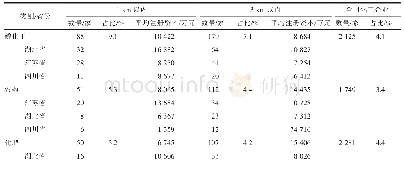
大数据技术以及聚类、挖掘分析等分析方法在图书馆的应用,为精细化服务以及个性化服务提供了新思路。如何在浩瀚的资源中定位到有一定特色的资源,如何在茫茫人海中找到某一特定的人群是这个问题的关键。因此,图书馆的大数据平台必须有一套工具用来“找人”和“找书”,不断精细化资源和人群的范围,针对不同精细化的人群提供特定的服务,而迭代分析就是为实现由粗到细的筛选分析方法。迭代分析就是通过行为、用户、资源维度逐层钻取关联分析得到更精准细化的(用户或资源)群体或行为现象。图3是本文提出的一种迭代工具设计思路。首先在读者模型中找到一种行为进行分析,获得的结果增加读者另一个维度进行分析可以获得一个范围的群体。将这个分析结果关联到资源的一个维度,获取到一个资源的群体,当结果再次选定一种用户行为时,就完成了一个迭代周期。根据这样的分析方法迭代下去,就会获得更精细的分析结果(读者群体或资源群体)。通过对数据结果不断地由粗到细、由大变小的筛选、过滤、剔除不符合条件的数据结果集,就会得到最终需要的数据结果内容。对这些数据集打标签,对每个读者或资源进行统一的打标签处理,从而实现数据结果的永久保存,并可按照该维度进行统计分析。
| 图表编号 | XD0042930400 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.02.10 |
| 作者 | 杨帆 |
| 绘制单位 | 国家图书馆 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}