《表3 流水线测试样例:模型驱动的大数据流水线框架PiFlow》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
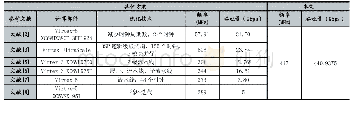
为验证PiFlow的性能,针对该场景与Apache NiFi进行了对比测试,共设计了4条流水线,测试流水线如表3所示。F1功能为DBLP数据采集入库,F2~F4为读取Oracle数据写入Hive。测试使用5台物理机搭建的集群环境,每台物理机为32核CPU,内存为128 GB。性能对比测试结果见表4,针对每条流水线的运行时间分别进行了三次测试,结果取平均值(见平均耗时)。其中PiFlow性能提升比例公式为:PiFlow性能提升比例=NiFi平均耗时/PiFlow平均耗时-1。Apache NiFi所需资源如表5,PiFlow所需资源如表6。Apache NiFi采集Oracle数据库的策略为将数据进行分页,每页10 000条数据,以页为单位进行并发读写。PiFlow采用分区方式进行读写,所采用的线程数与Apache NiFi相同。由于Apache NiFi基于FlowFile文件形式计算,而PiFlow基于内存计算,针对设计的4条流水线PiFlow相较Apache NiFi平均性能提升了5倍,且数据量越大优势越明显。
| 图表编号 | XD00163188400 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.06.10 |
| 作者 | 朱小杰、赵子豪、杜一 |
| 绘制单位 | 中国科学院计算机网络信息中心、中国科学院计算机网络信息中心、中国科学院大学、中国科学院计算机网络信息中心、中国科学院大学 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}