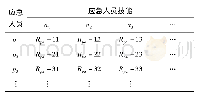
《表1 多GPU任务分配情况》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《基于多线程多GPU并行加速的最小二乘逆时偏移算法》
分别使用1~4个GPU进行1次迭代最小二乘逆时偏移计算。表1所示为使用不同个数GPU时,分配给各GPU的炮集数,以1个GPU计算耗时为参考值,计算各个GPU理论上的耗时情况,当GPU个数为3时,分配给GPU2设备的炮集数为7,则理论上,GPU2的耗时应该为GPU2计算20个炮集数据所用时间的7/20倍,以此类推。模型测试1中,参与计算的GPU个数与耗时情况如图13所示,黑色实线为实际耗时情况,可看出计算耗时随GPU个数增加而降低,多GPU加速效果较为明显;红色点划线为根据表1中的分配情况,多GPU并行算法达到理想化完全线性加速时理论上的耗时情况;蓝色虚线所示为各个GPU计算每个炮集数据的平均耗时。从图13中可看出,本文方法的执行效率较高,耗时情况接近线性加速,但随着GPU个数的增加,算法的实际执行效率有所降低。这是由于多GPU并行计算时,需等待最慢的线程完成计算任务,还需要执行梯度、更新步长等参数的同步计算,因此无法完全实现线性加速,从而导致随着GPU个数的增加,平均每个炮集数据的计算耗时略有增加。
| 图表编号 | XD0042270700 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.01.25 |
| 作者 | 柯璇、石颖、张伟、张振、何伟 |
| 绘制单位 | 东北石油大学地球科学学院、东北石油大学地球科学学院、东北石油大学地球科学学院、中国石油塔里木油田分公司勘探开发研究院、中石化石油工程地球物理公司南方分公司 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}