《表7 PKU XMedia数据集上的基线实验结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
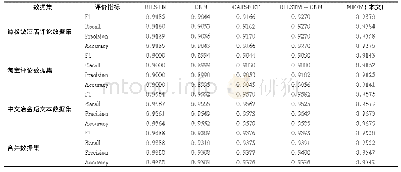
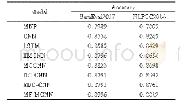
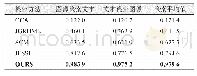
为了验证本文方法各个部分的效果,我们进一步进行了基线实验的对比,其中,“无三元组损失”表示去掉语义对齐关联损失函数(见公式 (5)) 中的三元组损失函数(见公式 (7)) 部分,“无MMD损失”表示去掉分布对齐关联损失函数(见公式 (8)) ,“基线方法”表示同时去掉上述两个部分,仅使用语义类别信息(见公式 (6)) 来约束不同媒体类型数据到统一空间的映射.从表7和表8可以看出,仅使用语义类别约束的平均检索准确率也同样高于3种对比方法的结果,表明充分利用数据内部的细粒度上下文信息能够更有效地建模不同媒体类型数据之间的关联关系,而三元组损失函数和分布对齐损失函数能够使模型在拥有语义辨识能力的同时,有效地将不同媒体类型数据的分布在统一空间内对齐,进一步提高了跨媒体检索的准确率.
| 图表编号 | XD0039648000 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.04.01 |
| 作者 | 卓昀侃、綦金玮、彭宇新 |
| 绘制单位 | 北京大学计算机科学技术研究所、北京大学计算机科学技术研究所、北京大学计算机科学技术研究所 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}