《表7 各分类算法在功能级双向流数据集上的实验结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
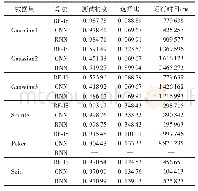
在功能级的移动互联网数据集上的分类结果如表7、8所示。实验结果表明,在双向流和单向流统计特征描述的流量数据集上,随机森林获得最高的总体分类准确率(0.795、0.827),最高的g-mean (0.768、0.800)和最高的F-measure (0.787、0.819),其次是Ada Boost。在功能级的数据集上KNN比C4.5的性能高一些,KNN是基于最近邻的方法,通过计算测试样本的K个近邻预测测试样本的类别标签。功能级的流量数据集上相同类别的样本聚集度相比App级流量数据高一些,为此KNN的性能更好;分类结果也说明不同移动App的相同功能产生的流量具有较高的相似度。
| 图表编号 | XD00222777100 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.11.05 |
| 作者 | 黄燚、刘珍、王若愚、陈洁桐 |
| 绘制单位 | 广东药科大学医药信息工程学院、广东药科大学医药信息工程学院、华南理工大学信息网络工程研究中心、广东省计算机网络重点实验室、广东药科大学医药信息工程学院 |
| 更多格式 | 高清、无水印(增值服务) |

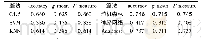



{kind=link}