《表1 不同λ值对分类的影响》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
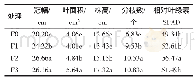
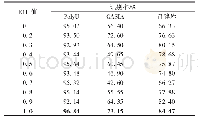
挖掘并将数据模式结构信息用于数据分类的HDCM通过混合传统分类方法和高级分类方法两种类型的分类技术来弥补传统分类方法仅仅采用数据物理特征进行模型训练及分类的缺陷。HDCM包含的两种不同类型分类技术在数据分类过程中所起的作用不同,如图5所示,当数据之间关联紧密,数据具有典型的模式结构时(蓝色“■”类),HDCM在分类过程中将以高级分类方法为主导,即公式(14)中参数λ的取值偏大。这里将通过图5所示的数据集具体地演示参数λ如何平衡HDCM中两种不同类型分类器对数据分类所起的作用。图5所示的数据集“·”类包含500个样本,“■”类包含的样本数为40,实验中选取广泛使用的SVM作为比较算法[1],算法相关参数设置如下:对于线性SVM,惩罚系数C=28;高斯型SVM中惩罚系数C=28,核宽度σ=2-3;混合分类方法中截断距离dc=1,参数k=5以及公式(11)中平衡系数γ=0.1。表1记录了参数λ取不同值时采用不同分类方法计算的测试样本(“▲”)对于数据集中不同类数据的隶属度,其中,普通分类方法对应Blue列,HDCM对应Red列。
| 图表编号 | XD0036352300 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.04.25 |
| 作者 | 王惠宇、顾苏杭 |
| 绘制单位 | 常州轻工职业技术学院信息工程学院、常州轻工职业技术学院信息工程学院、江南大学数字媒体学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}