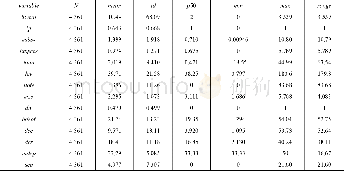
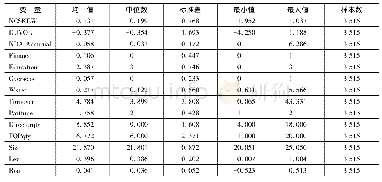
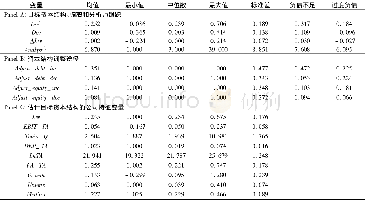
《表2 主要变量的描述性统计》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《普通话能力与农民工工资——来自“中国企业-劳动力匹配调查”的实证解释》
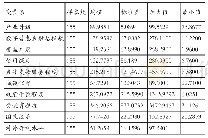
注:企业利润和资产总额为企业数据的2015年指标。
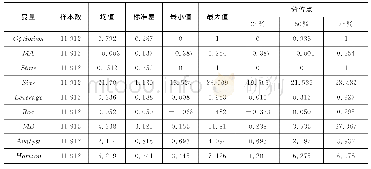
方程左边,ln(Monthly wage)作为被解释变量指员工月工资的自然对数(1)。方程右边,αi是常数项,自变量Mandarini指的是农民工的普通话能力,其系数β1指在控制其他因素后,不同普通话能力的回报率;Xi'代表个人特征向量,包括年龄及其平方项、性别(女性=0,男性=1)、婚姻(无配偶=0,有配偶=1)、健康(不好=1,一般=2,好=3)、教育程度(取值范围为0-22年);Worki'指员工的工作情况向量,包含工作身份(中高层管理人员=1,其他管理人员 (包括其他办公室工作人员)=2,技术人员或设计人员=3,销售人员=4、一线工人=5,其他员工=6) ,此外,为解决由于仅包含明瑟方程的有关变量而可能引起的遗漏变量偏误问题,本文将上一份工作结束时的工资作为控制变量,不仅避免农民工的选择性就业和外部市场机会等因素对农民工工资的影响,还避免农民工智商、情商、工作能力等难以统计因素的影响,同时,避免农民工以上一份工作的工资水平作为选择下一份工作的参照标准而产生的影响[23];Enterprisei’指的是企业层面影响农民工工资的相关因素向量,选取变量有企业利润、资产总额、是否为出口企业(不出口=1,加工贸易出口=2,出口但不是加工贸易出口=3)、企业所有制类型(国有企业=1,民营企业=2,外资企业=3,其他类型=4)和企业规模(2)(小型企业=1,中型企业=2,大型企业=3)。此外,Dj、Dd分别为行业和地区的固定效应。根据上述模型的构建,主要变量的描述性统计结果如表2所示。
| 图表编号 | XD0036192300 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.04.01 |
| 作者 | 程虹、王岚 |
| 绘制单位 | 武汉大学质量发展战略研究院、武汉大学质量发展战略研究院 |
| 更多格式 | 高清、无水印(增值服务) |

{kind=link}