《表3 ABCD, EFGH和NOPQ数据集概念定义表》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
注:+代表正类,-代表负类
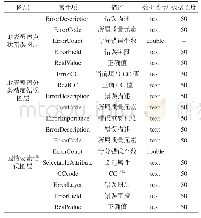
Letter数据集共包含16维连续属性,26个字母,20000个样本。本文使用Letter数据集中的字母ABCD制作ABCD数据集,使用字母EFGH制作EFGH数据集,使用字母NOPQ制作NOPQ数据集。Letter原始数据集中并未包含概念漂移,为了产生概念漂移,Letter数据按照RTG数据集类似的方式重新标注正类和负类的类别标签,从而产生概念漂移。在各个字母产生的概念漂移数据集中,ABCD数据集、EFGH数据集和NOPQ数据集均包含3个新概念。为了使数据流中包含更多的概念并且考虑到数据量的关系,按照表3的顺序将每个新概念依次重复1次,之后再将第1个和第2个新概念再重复1次,因此共产生8个概念。在ABCD数据集、EFGH数据集和NOPQ数据集中,除最后一个重复概念外,每个概念均包含400个样本,每个字母各100个样本,所有的样本均为随机选择。将每个字符中剩余的数据组成最后一个重复概念。ABCD数据集、EFGH数据集和NOPQ数据集的概念分布如表3所列。
| 图表编号 | XD0035512600 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.01.15 |
| 作者 | 秦一休、文益民、何倩 |
| 绘制单位 | 桂林电子科技大学计算机与信息安全学院、桂林电子科技大学计算机与信息安全学院、广西可信软件重点实验室桂林电子科技大学、桂林电子科技大学计算机与信息安全学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}