《表1 词向量示意Tab.1 Word vector》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
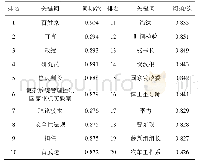
(2) 建立词向量,将文本进行数学化表达,作为训练模型的输入。这里使用了搜狐的互联网语料库进行jieba分词后,利用Word2Vec中的CBOW训练词嵌入(word embedding),将自然语言中的字词转为计算机可以理解的稠密向量,核心思路即“用词附近的词来表示该词”。在Word2Vec出现之前,自然语言处理经常把字词转为离散的单独的符号,也就是One-Hot Encoder Word,每个词用长向量表示,向量维度是词表大小。向量中只有一个值为1,其余都为0。这种方法存在以下问题。一方面,单词编码是随机的,向量之间相互独立,看不出各个单词之间可能存在的关联关系。其次,向量维度的大小取决于语料库中字词的多少。如果将所有单词对应的向量合为一个矩阵的话,矩阵过于稀疏,会造成维度灾难(一个大的语料库维度超过几十万)。而Word2Vec将一个词所在的上下文中的词作为输入,而那个词本身作为输出。通过对一个大的语料库训练,得到一个从输入层到隐含层的权重模型。训练完成后,就得到了每个词到隐含层的每个维度的权重,就是每个词的向量表示(维度一般在50~100)。对于句子“My major is computer science.”“my”与其它单词之间距离见表1。其可视化表示如图2所示。
| 图表编号 | XD0030164500 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.01.01 |
| 作者 | 盛成成、朱勇、刘涛 |
| 绘制单位 | 南京工程学院计算机工程学院、南京工程学院计算机工程学院、南京工程学院计算机工程学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}