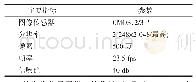
《表2 特征提取结果:基于改进的TF-IGM热词提取算法研究》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
从图1中可以看出,开始时特征词项数较小,因此选择的特征项F1的值在0~400间波动较大,TF-IGM模型由于考虑文档词项分布,相比传统的TF-IDF在特征词项数目较小时,能够较好的反映特征词在文本空间中的权重,随着词项数的增加,选择的词项在向量空间中趋于稳定,说明特征词在某个文本空间中具有稳定性的特征。另外,改进的TF-IGM模型将文档频率和词项在文档间的分布分开,能够很好地描述词项权重,并且由实验结果可知,评估值略高于TF-IGM模型。表2表示当N=M=200时的特征提取精度对比。
| 图表编号 | XD0024691700 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2018.03.25 |
| 作者 | 朱杰 |
| 绘制单位 | 河海大学计算机与信息学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}