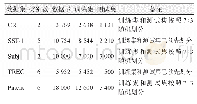
《表4 模型参数量:融合特定任务信息注意力机制的文本表示学习模型》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
首先,各模型的参数数量如表4所示。除了Self Att模型参数达到千万级外,FTIA与LSTMAtt、Bi GRU等模型参数同处于百万级,仅比LSTMAtt多0.9%的参数。结合表3的准确率对比,可见FTIA能通过较小规模的参数集获得更优的文本理解及表达能力,进一步验证FTIA模型的可行性。
| 图表编号 | XD00227027500 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.09.25 |
| 作者 | 黄露、周恩国、李岱峰 |
| 绘制单位 | 中山大学资讯管理学院、中山大学资讯管理学院、中山大学资讯管理学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}