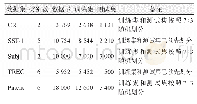
《表1 数据描述性统计:基于双注意力机制和迁移学习的跨领域推荐模型》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本文在Amazon数据集中选择“电影”、“图书”和“CD”作为实验数据,将其分为“电影-图书”和“电影-CD”两个跨领域组合进行实验分析.首先对数据进行稠密度的预处理,保留三组数据中具有10条以上评论的用户,“图书”和“电影”中超过120条评论的项目,“CD”中超过30条评论的项目,随后从“电影-图书”和“电影-CD”跨领域组合中选择有交互的用户.“电影”的稠密度相比于“图书”和“CD”的稠密度更大,因此在跨领域组合中将“电影”作为源域,“图书”和“CD”分别作为目标域.其次对评论文本进行分词、删除停用词、用Nltk(2)进行词形的还原等处理,数据集统计信息如表1所示.
| 图表编号 | XD00197658200 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.10.01 |
| 作者 | 柴玉梅、员武莲、王黎明、刘箴 |
| 绘制单位 | 郑州大学信息工程学院、郑州大学信息工程学院、郑州大学信息工程学院、宁波大学信息科学与工程学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}