《表2 不同施氮水平下的预测集识别效果对比》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《基于高光谱和参数优化支持向量机的水稻施氮水平分类研究》
(%)
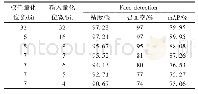
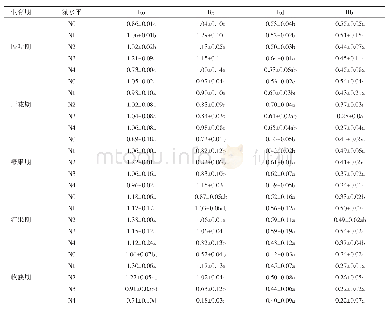
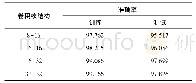
采用默认参数及3种寻优方法进行支持向量机的水稻氮素营养分类识别模型建立,建模测试集各施氮水平识别效果如表2所示。从整体来看,默认参数下的SVM模型测试集平均识别效果最差,仅为87.500%,3种寻优方法的SVM模型测试集实验效果较默认参数下的SVM模型要好,均达到95.000%及以上,其中以基于遗传算法优化SVM模型(GA-SVM)实验效果最佳,高达98.750%,较基于网格搜索算法优化SVM模型(Grid-SVM)和基于粒子群算法优化SVM(POS-SVM)分别高出3.75%和2.50%。从各施氮水平识别效果来看,默认参数下的SVM模型在第二类(低氮)施氮水平上识别陷入局部最小,第二类(低氮)识别准确率仅为65.00%,其他3类(第一类、第三类、第四类)施氮水平均达到95.000%,默认参数下的SVM模型各施氮水平识别分类结果如图7所示。其他3种参数优化的SVM模型对第三类(中氮)、第四类(高氮)施氮水平都能够很好地识别,达到100.000%,对第二类(低氮)施氮水平的识别都达到了95.000%。只有在第一类(不施氮)施氮水平上,识别效果产生了一定的差别。基于遗传算法的SVM模型较其他两种优化算法优化的SVM模型,仅第二类(低氮)施氮水平下的第40组样本被误判为第三类(中氮)施氮水平;基于网格算法优化的SVM模型中,第一类(不施氮)施氮水平下的第12、13和14组样本被误判为第二类(低氮)施氮水平,第二类(低氮)施氮水平下的第40组样本被误判为第三类(中氮)施氮水平;基于粒子群算法优化的SVM模型中,第一类(不施氮)施氮水平下的第12和14组样本被误判为N1施氮水平,第二类(低氮)施氮水平下的第40组样本被误判为第三类(中氮)施氮水平;而基于遗传算法优化的SVM模型仅将第二类(低氮)施氮水平下的第40组样本被误判为第三类(中氮)施氮水平。3种优化算法优化SVM模型的各施氮水平识别分类结果如图8、9、10所示。
| 图表编号 | XD00226422500 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.10.10 |
| 作者 | 罗建军、杨红云、路艳、万颖、孙爱珍、易文龙 |
| 绘制单位 | 江西农业大学计算机与信息工程学院、江西农业大学软件学院、江西省高等学校农业信息技术重点实验室、江西农业大学计算机与信息工程学院、江西农业大学计算机与信息工程学院、江西农业大学计算机与信息工程学院、江西农业大学软件学院、江西省高等学校农业信息技术重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |
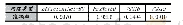


{kind=link}