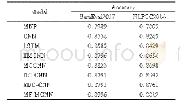
《表1 不同模型在Twitters Sarcasm数据集上是实验结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
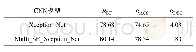
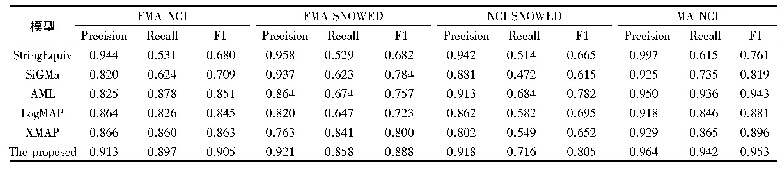
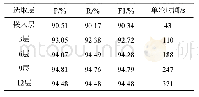
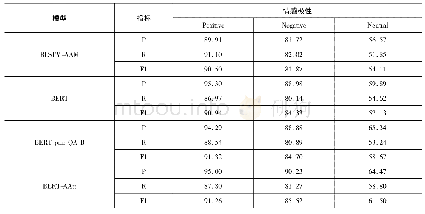
本文采用精确率(Precision)、召回率(Recall)、F1值(F1 score)和准确率(Accuracy)作为模型的评价标准。各模型在反讽数据集Twitters Sarcasm的实验结果如表1所示。结合图文数据进行反讽识别的模型MIRM相较于仅对文本数据进行反讽识别的Text CNN模型、Bi GRU模型和Bi GRU-ATT模型效果都要好。本文所提出的模型相比于文本分类模型BiGRU和TextCNN,准确率提高了4%和3.5%。这也证实了相比单一的文本数据,结合图文信息能更好地理解反讽表达。
| 图表编号 | XD00220093900 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.08.25 |
| 作者 | 林敏鸿、蒙祖强 |
| 绘制单位 | 广西大学计算机与电子信息学院、广西大学计算机与电子信息学院 |
| 更多格式 | 高清、无水印(增值服务) |

{kind=link}