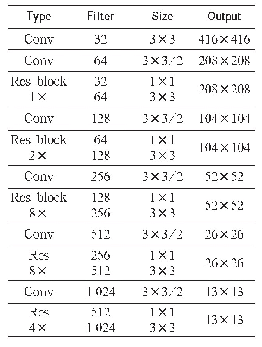
《表1 Darknet53特征提取网络》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
YOLO是一种端到端的基于深度学习的目标识别方法。YOLOv3与R-CNN等目标识别方法不同,不需要特意提取候选框区域,从而可以大幅度提高目标检测的速度,但是当多个目标的中心存在于同一网格内时,YOLOv3方法只能识别出一个物体目标。虽然目标检测精度相比于R-CNN等网络较低,但是在目标检测的速度方面有很大的提升。随后,2017年,作者提出改进的YOLOv2目标检测识别算法,比YOLO速度更快,识别效果更好,但仍然在精确度上有待提高。2018年,作者继续提出改进的YOLOv3版本,该网络整体架构基于Darknet-53特征提取网络,如表1所示,该特征提取网络比YOLOv2做了进一步提升。Darknet-53作为一个新兴的特征提取架构,由多个3×3和1×1卷积核进行卷积,包含了53个卷积层和多个残差结构,是Darknet-19的进一步提升。YOLOv3使用特征金字塔的概念,通过三个不同的尺度上提取特征来对图像进行包围框预测。为了获取更有价值和更具精细的图像信息,浅层特征图将和深层特征图进行合并,继续进行进一步的处理。与Faster R-CNN类似,YOLOv3同样适用logistic回归对包围框进行预测,但是每个ground truthobject只分配一个包围框。最终,YOLOv3由75层卷积层和3个预测层组成。
| 图表编号 | XD00218689600 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.12.25 |
| 作者 | 孙旭升、张林、于正同 |
| 绘制单位 | 中国航空工业集团公司西安航空计算技术研究所 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}