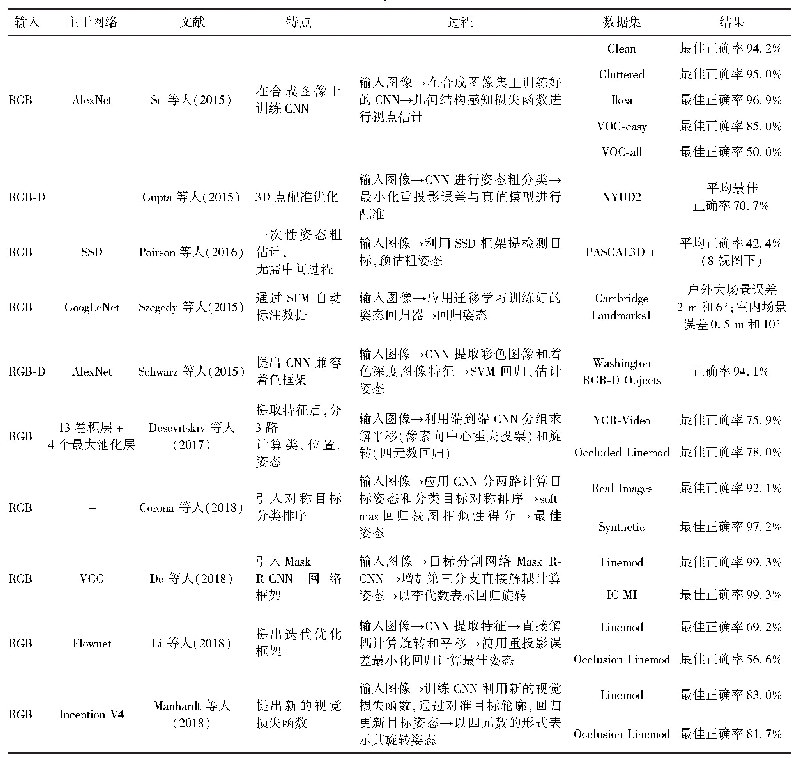
《表2 直接法的特征概括:单幅图像刚体目标姿态估计方法综述》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
注:“-”表示无该主干网络介绍。
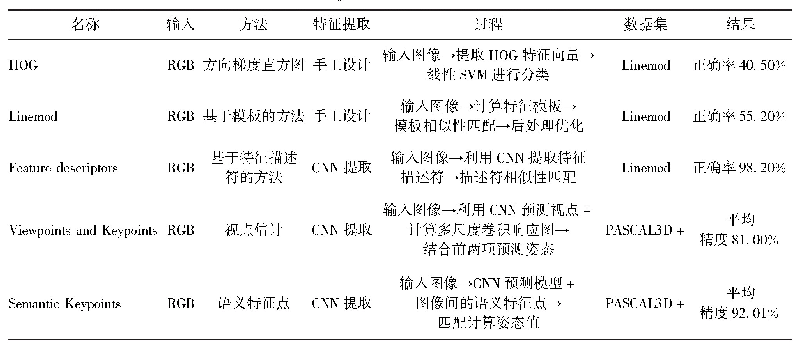
2)直接法。大多数姿态估计的深度学习方法都属于直接计算的方法,依靠深度CNN提取原始图像特征,然后将特征图送入专门构建的姿态估计分支、目标类估计分支和语义分割分支等,最终得到图像中各目标实例的姿态信息。如表2所示,直接法主要有分类和回归两种方法。分类是对目标模型进行高粒度离散视图采样,形成离散的真值姿态空间,比对观测图像与真值图像的一致性,将姿态估计问题转化为图像分类问题(Gupta等,2015;Su等,2015;Poirson等,2016),其中,Gupta等人(2015)以CNN进行姿态粗分类,再以最小化重投影误差与真值模型进行配准;Su等人(2015)训练CNN在合成图像上进行视点姿态分类;Poirson等人(2016)基于SSD检测器直接在多个离散化BB网格上检测目标估计姿态,将姿态估计问题转化为姿态分类问题。但是,此类方法存在估计精度不高、依赖姿态优化环节和视图采样数量随目标实例数量不断增长等不足。回归是利用回归计算的思想,以损失函数最小化的方式多次计算,回归至真值,将姿态估计问题转化为姿态回归问题(Kendall等,2015;Schwarz等,2015;Xiang等,2017;Corona等,2018;Do等,2018;Li等,2018;Manhardt等,2018)。其中,Kendall等人(2015)在Goog Le Net(Szegedy等,2015)网络基础上改进并提出了Pose Net姿态估计网络,通过SFM(structure from motion)完成对数据集真值姿态的自动标注,以CNN回归计算未知姿态;Schwarz等人(2015)利用CNN提取彩色图像和着色深度图像特征,然后由支持向量机回归估计目标姿态;Xiang等人(2017)在计算光流网络Flownet(Dosovitskiy等,2015)的基础上,提出Pose CNN姿态估计网络,通过CNN提取的卷积特征,分三路分别获取目标类信息、位置信息和姿态信息,以回归计算的方式,采用四元数的形式表示和估算姿态;Corona等人(2018)通过12面体视图采样后,应用CNN分两路计算目标姿态和分类目标对称排序,以softmax回归视图相似性得分,得到最佳姿态;Do等人(2018)在卷积神经网络VGG(Simonyan和Zisserman,2014)为主干框架的基础上,引入基于目标分割网络Mask R-CNN(He等,2017),增加第三分支直接解耦计算姿态,以李代数表示回归旋转;Li等人(2018)应用CNN提取特征,直接解耦计算旋转和平移,并使用重投影误差最小化回归计算最佳姿态并将提出的方法命名为DeepIM姿态估计网络;Manhardt等人(2018)已知初始估计值,利用Inception V4(Szegedy等,2017)模块,结合新的视觉损失函数,通过对准目标轮廓,训练CNN回归更新目标姿态,且其旋转姿态以四元数的形式表示。
| 图表编号 | XD00216433400 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2021.02.16 |
| 作者 | 杨步一、杜小平、方宇强、李佩阳、王阳 |
| 绘制单位 | 航天工程大学、航天工程大学、航天工程大学、航天工程大学、航天工程大学 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}