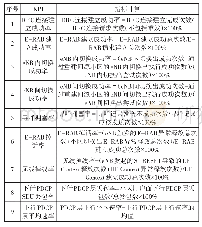
《表1 数据集划分:基于机器学习的用户升级预判研究》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
将样本数据按比例7∶2∶1分为3份,分别作为训练集、验证集和测试集,如表1所示。其中训练集用来对模型进行训练;验证集则在训练过程中对训练模型进行验证,提前终止训练,令模型保持在最优状态;测试集则对各个模型进行评估。由于正负样本数量相差悬殊(达到1∶62),直接输入模型,如果模型将所有样本都预测为负样本,则准确率就能达到98.3%,显然不是期望的目标。因此在训练过程中,一般对负样本进行随机采样,使得正负样本比例达到1∶1。测试集则不需要采样处理。
| 图表编号 | XD00213953900 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2021.01.15 |
| 作者 | 高和、籍汉超、陈玲 |
| 绘制单位 | 中国联通研究院、亿览在线网络技术(北京)有限公司、中国联通研究院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}