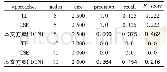
《表1 Binary Alphadigits数据集实验结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
各个算法的平均准确率如表1所示。根据表1中的结果,在Binary Alphadigits数据集上,基于不确定性采样的主动学习模型的平均性能最好,达到的平均准确率最高。结合图4可知,基于密度加权的主动学习算法在查询样本数较少的情况下能够达到较高的准确率,但是随着查询数的增多,分类性能却提升不多,使得最终的平均准确率与随机抽样的方法相差不大。随着每个子集上需要判别的类别数的增多,各个主动学习算法在Binary Alphadigits数据集上的平均准确率都有不同程度的下降。但在子抽样集包含3类样本时,所有算法的准确率都达到了83%以上,相较于传统主动学习算法直接处理这类样本的实验准确率有较大提升,证明本文提出的主动学习框架是有效的。
| 图表编号 | XD00213540200 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2021.03.01 |
| 作者 | 施伟、黄红蓝、冯旸赫、刘忠 |
| 绘制单位 | 国防科技大学系统工程学院、国防科技大学系统工程学院、国防科技大学系统工程学院、国防科技大学系统工程学院 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}