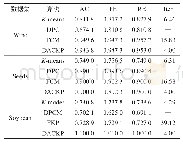
《表1 数据集A和数据集A+的实验结果比较》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《基于深度层级特征的中国传统视觉文化符号识别及应用》
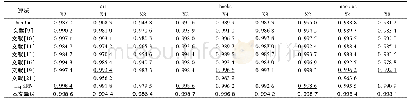
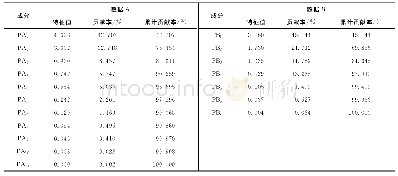
主要根据局部特征和全局特征的优势互补性,将几种特征结合在一起形成多特征,我们分析了几种特征组合的识别结果,即SIFT+RGB,SIFT+RGB+LBP,SIFT+HOG+RGB等,其中在SIFT特征提取过程中,我们引用了词包模型和空间金字塔的思想[1],使得提取到的特征具有空间语义信息。同时,根据对视觉文化符号的特征分析,我们在提取SIFT特征的基础上,又加入了轮廓特征和颜色特征等,并将以上几种特征融合,将融合后的特征作为图像的具有空间语义信息的特征表达。并用核函数为的SVM作为文化符号的分类器来将文化符号分类。实验中,使用的数据是从视觉文化符号数据集中抽取的典型的8类符号作为数据集A,实验证明,基于浅层学习的中国传统视觉文化符号识别算法中,最有效的识别算法组合是含有空间位置信息的SIFT、HOG和RGB融合的多特征,并结合核函数为的SVM作为分类器,识别的平均F-值在97.5%左右。但考虑到实际生活中识别系统的拒识能力和泛化能力,我们对正样本进行了数据扩充并加入了负样本,此时数据集A变为数据集A+,也就是在数据集A+上再次使用前面的方法进行实验,实验结果如表1所示。从表1中,可以发现,当识别任务变复杂后,准召率明显下降,F-值降低了约6个百分点,对实验结果进行错误分析后,我们觉得在分类任务变复杂后,使用浅层学习的SIFT+HOG+RGB(SPM)方法并不能够很好地完成分类任务。这就说明浅层学习在处理复杂的分类任务上,效果并不理想,所以我们对于这一问题的解决还需要进一步研究。
| 图表编号 | XD002530700 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2018.04.25 |
| 作者 | 吴晓雨、张愉、谭笑、杨磊 |
| 绘制单位 | 中国传媒大学信息工程学院、中国传媒大学信息工程学院、中国传媒大学信息工程学院、中国传媒大学信息工程学院 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}