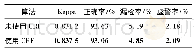
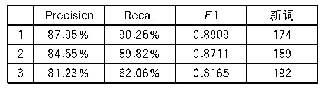
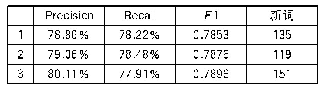
《表6 各方法术语抽取结果对比(统计学方法展示排序前10的结果,CRF及Bi-LSTM+CRF方法展示未出现于训练语料中的任意10个结果)》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
在统计学方法使用前采用语言学模板提取候选术语,相比采用N-gram模型能够有效地提升统计学术语抽取效率。实验发现一些低频词性模板是噪声模板(例如错误的分词引入的词性组合、关键词“A和B”等非术语引入的词性组合等),仅采用高频词性模板能够提升抽取效率。利用词性组合在集合中占有的比重来近似模型权重,能有效地提升统计方法对一元术语抽取的效率。移除高频词、低频候选术语以及子串归并能够有效地提升TF-IDF、KLI等方法的效果;然而对于C-value、KLP等依赖于父串、子串信息的方法有不利影响,因为删除高频、低频和子串信息后,这些方法计算出的结果不能体现真实排序。统计学方法均是基于词频的方法,因此对于抽取低频术语效果不佳。CRF方法在抽取低频术语时有较好的表现。考虑词频、词长、词性组成、词性构成比重、父串和子串信息、上下文词信息、引入外部语料等均有利于术语的抽取。针对统计学方法去除每一种方法结果中的异常大或异常小的数值,再对各结果进行标准化,最后根据每一种方法的效率来分配权重求综合值,这种方法可以弥补单一方法考虑信息不全和极端值的问题。虽然基于机器学习的方法(CRF、Bi-LSTM+CRF)抽取术语测评结果的各项指标中均要高于统计学方法,但是统计学方法依然是有一定意义的。从新词抽取的结果上可以看出(见表6),统计学方法可以有效地发现领域中的新词而无需标注语料。
| 图表编号 | XD00213463700 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2021.01.26 |
| 作者 | 蒋婷 |
| 绘制单位 | 南京财经大学信息工程学院 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}