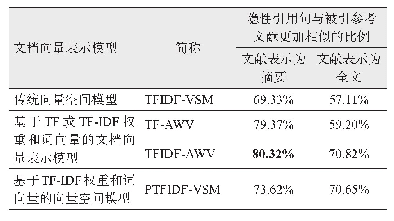
《表3 基于各种文档向量表示模型的隐性引用句与施引/参考文献的相似度比较结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
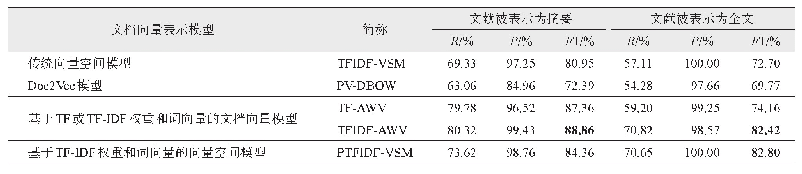
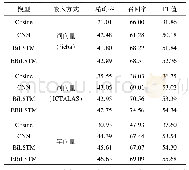
采用上述实验语料对3.1节提出的假设“与所在的施引文献相比,隐性引用句与被引参考文献在内容上更加相似”进行验证。在实际中,由于文献的全文往往难以获得,因此该实验采用摘要和全文两种方式来表示文献。首先采用不同的文档向量表示模型表示隐性引用句、施引文献(全文或摘要)和被引参考文献(全文或摘要),然后比较每个隐性引用句与其所在的施引文献和所提及的被引参考文献之间的余弦相似度。采用不同文档向量表示模型的比较结果如表3所示。可以看出,无论采用哪种文档向量表示模型,无论文献采用摘要还是全文表示,超过一半的隐性引用句(至少57.11%)都与其被引参考文献更加相似。采用基于TF-IDF权重和词向量的文档向量表示模型和文献摘要,效果更加显著,有超过80%的隐性引用句与被引参考文献更加相似。此外,采用文献(包括施引和被引参考文献)的摘要代替全文,隐性引用句与被引参考文献的相似程度更加明显,这是因为引用句往往是对被引参考文献内容的概括,而摘要同样是概括性的,因此引用句与摘要的语义相似度要比全文更高。实验结果表明,本文提出的基于文本相似度的隐性引用句识别方法具有很高的合理性和可行性。
| 图表编号 | XD00212863800 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2021.01.25 |
| 作者 | 金贤日、欧石燕 |
| 绘制单位 | 南京大学信息管理学院、南京大学信息管理学院 |
| 更多格式 | 高清、无水印(增值服务) |


{kind=link}