《表3 本文方法与其他方法抽取双语词汇的准确率》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
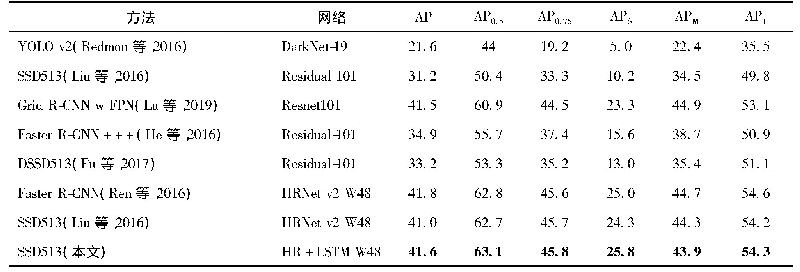
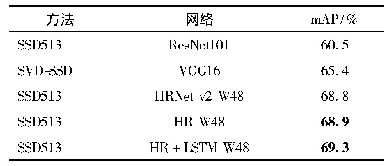
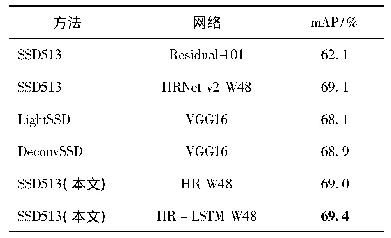
由表3可知,我们提出的方法可以显著提高汉缅双语词汇的准确率.实验结果也表明明显优于其他几种方法,同基于双语LDA+CBW的方法相比,本文方法准确率提升了3.82%,主要原因在于BERT不仅仅是只关注一个词前文或后文的信息,而是整个模型的所有层都去关注其整个上下文的语境信息,得到更好的上下文特征表示向量.同基于双语词典的方法和基于枢轴语言的方法相比,本文方法准确率分别提升了11.07%和13.27%.主要原因在于基于双语词典的方法未考虑到双语可比文档的主题特征对候选翻译的有效约束和基于枢轴语言的方法容易出现一词多译,错译等问题.
| 图表编号 | XD00212236700 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2021.01.01 |
| 作者 | 李越、毛存礼、余正涛、高盛祥、王振晗、张亚飞 |
| 绘制单位 | 昆明理工大学信息工程与自动化学院、昆明理工大学信息工程与自动化学院、昆明理工大学云南省人工智能重点实验室、昆明理工大学信息工程与自动化学院、昆明理工大学云南省人工智能重点实验室、昆明理工大学信息工程与自动化学院、昆明理工大学云南省人工智能重点实验室、昆明理工大学信息工程与自动化学院、昆明理工大学云南省人工智能重点实验室、昆明理工大学信息工程与自动化学院、昆明理工大学云南省人工智能重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |

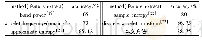

{kind=link}