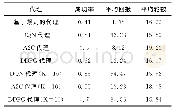
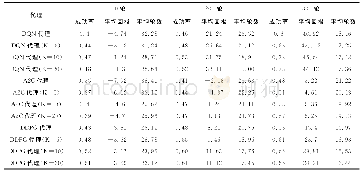
《表2 不同代理在epoch={100,200,300}回合的表现》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
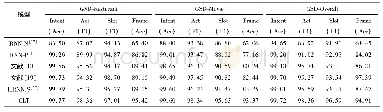
通过表2可知在代理学习的开始阶段,DDPG代理的学习速度要高于其它的代理,其主要原因是本文采用确定性策略能够帮助代理更快找到成功的对话策略,而在学习的后面阶段(300轮左右),结合规划的DDPG代理学习速率要低于DQN代理,其主要是因为DDPG代理需要学习两种参数不同的神经网络:actor-online网络和critic-online网络,这两个网络存在学习不同步的问题,actor-online网络选择动作的优劣取决于critic-online网络的打分,在criticonline网络训练好之前,很难对actor-online网络进行有效的训练,而DQN代理只需要训练一种神经网络参数,并不存在多网络协作问题,所以它的效果要优于A2C、DDPG等代理。但是与A2C代理相比,本文所提出的方法要优于A2C代理,验证了从策略梯度角度出发,本文所提出的方法能够在一定程度上加快模型的收敛速度,带来更好的对话性能。
| 图表编号 | XD00208592900 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2021.02.16 |
| 作者 | 赵崟江、李艳玲、林民 |
| 绘制单位 | 内蒙古师范大学计算机科学技术学院、内蒙古师范大学计算机科学技术学院、内蒙古师范大学计算机科学技术学院 |
| 更多格式 | 高清、无水印(增值服务) |


{kind=link}