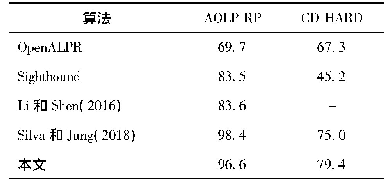
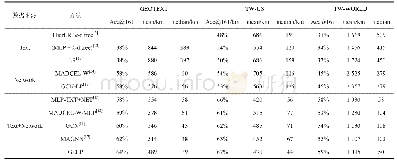
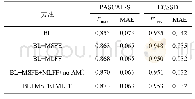
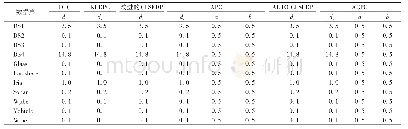
《表2 在2个非线性合成数据集和6个真实数据集上的性能比较》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
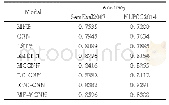
实验结果.表2展示不同算法在8个数据集上的表现.在每个数据集上,我们均进行了10次测试运行,并显示了平均正确率以及标准偏差.·(?)表示在95%显著性水平的成对t-检验意义下,Condor Forest算法明显优于(劣于)对比方法.表2显示,Condor Forest算法在5个数据集(总计8个数据集)上取得最优的性能,这体现了Condor Forest算法的有效性.此外,我们可以看到,在两个非线性的合成数据集上,Condor Forest算法显著优于Condor SVM算法.这是因为Condor SVM的基分类器是线性支持向量机,因此无法很好地拟合这类非线性数据.在其他6个真实数据集上,Condor Forest在其中4个数据集上取得了最优的性能.在Weather和Gas Sensor这两个数据集上,Condor Forest的表现不如Condor SVM,这可能是因为这两个数据集的数据分布相对而言比较散,线性可分性比较强,因此更加适合采用基于SVM的方法进行分类.值得注意的是,总体而言,在6个真实数据集上,Condor Forest和Condor SVM算法取得了最优,优于其他的对比方法(DWM,DTEL,TIX).这两种算法均采用模型重用机制以抵御流数据中的分布变化,这体现了模型重用机制的有效性.
| 图表编号 | XD00204794700 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2021.01.20 |
| 作者 | 赵鹏、周志华 |
| 绘制单位 | 南京大学计算机软件新技术国家重点实验室、南京大学计算机软件新技术国家重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |

{kind=link}