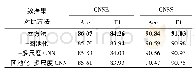
《表2 CVRNN代码分类消融实验》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
模型1直接将双向RNN移除,表示整个CVRNN模型将不提取代码的序列信息,而模型2将双向RNN替换成双层单向RNN则表示削弱模型提取序列信息的能力。表2展示了各个模型在代码分类上取得的精度,可以看出模型1在失去提取代码序列信息模块之后,分类精度直接从94.4%降到了73.8%,对比模型2的92.5%有很大的差距。表3展示了各个模型在相似代码搜索任务上的结果,可以发现,模型1虽然在失去提取序列信息的模块之后在代码分类任务上要明显逊色于模型2,在相似代码搜索各项度量指标上的值却都高于模型2,该结果也与问题3得到的结论相符合,模型在代码分类以及相似代码搜索上的性能并不是成正相关的。从表2以及表3可以看出,模型4在两个任务上的性能都要高于模型1和模型2。图8展示了模型3以及模型4在训练过程中每一轮在验证集上的分类精度。可以看出使用预训练词向量的模型4将收敛得更快,经过第一轮训练之后,模型3的分类精度为72.00%,而模型4精度能达到76.50%。并且在每一个训练轮次之中,使用预训练向量的模型都有更高的精度,使用预训练词向量的模型4最终达到94.4%的分类精度,而随机初始化词向量的模型最终的分类精度是91.4%。从表3也可以看出,预训练词向量对提升相似代码搜索的性能也有贡献。
| 图表编号 | XD00204322100 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2021.03.01 |
| 作者 | 史志成、周宇 |
| 绘制单位 | 南京航空航天大学计算机科学与技术学院、南京航空航天大学高安全系统的软件开发与验证技术工信部重点实验室、南京航空航天大学计算机科学与技术学院、南京航空航天大学高安全系统的软件开发与验证技术工信部重点实验室、南京大学软件新技术国家重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}