《表4 Fast Text模型分类结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
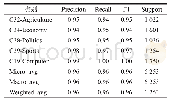
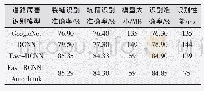
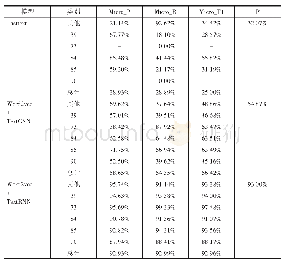
本实验选用Fast Text模型、Naive_bayes(朴素贝叶斯)模型、SVM模型分别进行分类训练,采用上述的测试集验证分类结果,三类模型的分类结果如表4~6所示。按照机器学习分类的评价标准,分别求出5类文本数据中每一类的精准率、召回率和F1值,并计算综合文本测试集的宏平均、微平均和加权平均精准率、召回率和F1值,同时显示每类的测试档案数量。
| 图表编号 | XD00201634200 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2021.03.15 |
| 作者 | 霍光煜、张勇、孙艳丰、尹宝才 |
| 绘制单位 | 北京工业大学信息学部多媒体与智能软件技术北京市重点实验室、北京工业大学信息学部多媒体与智能软件技术北京市重点实验室、北京市交通信息中心、北京工业大学信息学部多媒体与智能软件技术北京市重点实验室、北京工业大学信息学部多媒体与智能软件技术北京市重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}