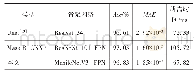
《表6 不同算法在Minst数据集上的新类检测性能》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
对所用的4个数据集进行预处理,消除数据集中的冗余数据和冗余特征。一个数据集随机选择两个类作为已知类,其余类为新类。进行10次实验,每次实验的训练样本与测试样本在数据集中随机选取,测试样本中已知类样本与新类样本比例设为2∶1。取10次结果平均值作为衡量KCRForest算法的性能指标。4个数据集上不同方法的新类检测性能见表3~表6,分类精度见图3。
| 图表编号 | XD00200923300 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2021.01.01 |
| 作者 | 武炜杰、张景祥 |
| 绘制单位 | 江南大学理学院、江南大学理学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}