《表3 分类结果比较:基于Stacking集成学习的流失用户预测方法》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
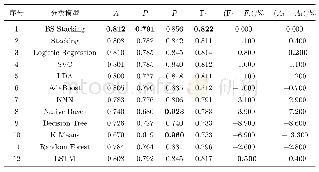
表3给出了各个分类模型的得分.其中经典Stacking集成方法在测试集中的得分比其最好的基分类器在F1度量上差0.3%,可见集成后分类效果没有提升,造成这种情况的一种可能是:基分类在训练集中对某些相同的样本均分类错误,使元分类器在错误的数据中训练,从而导致最后样本的分类错误.实验结果表明,BS-Stacking具有较高的分类准确率及流失用户的F1值得分.在基分类器中,Logistic Regression、SVC和Ada Boost具有相近的得分,其中得分最高的为Logistic Regression.BS-Stacking与Logistic Regression相比,F1值提高0.8%,准确率提高0.2%;与经典Stacking相比,F1值提高1.1%,准确率提高0.4%;与LSTM相比,F1值提高0.5%,准确率提高0.4%.BS-Stacking具有最高的准确率、查准率和F1值,具有最高召回率的是Native Bayes模型和K-Means模型,但是这两个模型的查准率远低于其他模型.
| 图表编号 | XD00200370300 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.11.30 |
| 作者 | 郑红、叶成、金永红、程云辉 |
| 绘制单位 | 华东理工大学信息科学与工程学院、华东理工大学信息科学与工程学院、华东理工大学信息科学与工程学院、上海师范大学商学院、华东理工大学信息科学与工程学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}