《表2 随机性检验输出结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
注:P值(Prob)就是当原假设为真时所得到的样本观察结果或更极端结果出现的概率。
由图3可知:D1分量为各个分量中最高频分量,其变化速率剧烈。经过数据对比后发现,D1分量的数据波动趋势与气象信息、时间信息、节假日信息的数据波动趋势并不吻合。针对最高频分量的预测问题,笔者考虑选择RF模型、BP神经网络、Logistic回归模型对其进行训练,并对5月24日至5月30日的最高频细节分量进行预测。在试验过程中发现采用RF模型时出现了测试集过拟合的问题;对于原始气象数据进行多重共线性筛选,并把筛选后的特征数据分别投入BP神经网络与Logistic回归模型进行预测,观察其预测效果(BP神经网络选用节假日信息、最高温度、最低温度、雨晴信息、风速信息作为输入层、日供水负荷作为输出层、转移函数采用Sigmoid函数,训练步长Show=50,学习速率β=0.03[18])。其中Logistic回归预测模型准确率只有53%,BP神经网络的数据拟合结果如图4所示。由图4可知:BP神经网络对5月24日与5月25日的实际供水负荷分量(D1分量)有较高的拟合度;但从整体来看:BP神经网络拟合曲线的走势与真实数据的走势并不相符,不符合对于预测结果所需要的精准度的需求。通过观察RF模型、BP神经网络、Logistic回归模型的运算方法与运算结果,发现有监督的机器学习对于本次试验的最高频供水负荷分量没有强烈的普适性,则考虑ARIMA模型对于本次试验所用到的数据的适用性。经过对D1细节分量进行ADF单位根检验发现P=0.998 37>0.05为接受原假设,即认为高频细节分量(D1)为平稳时间序列,同时对高频细节分量(D1)调用python中的Acorr_ljungbox()函数(数据纯随机性检验函数)进行随机性检验,检验结果P=0.000 779<0.05,为拒绝原假设,则对高频细节分量(D1)建立ARMA预测模型。其建立的ARMA预测模型参数如表1所示。对建立的模型进行残差随机性检验(Ljung-Box test检验),检验结果见表2。根据表2得Prob值均大于0.05得出结论:残差序列不存在自相关性[19]。即根据ARMA模型对于高频细节分量(D1)计算出的残差样本为白噪音样本,所以认为将高频细节分量(D1)用ARMA模型进行预测是适用的,其ARMA拟合曲线如图4所示。
| 图表编号 | XD00199657000 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.10.10 |
| 作者 | 刘志壮、吕谋、周国升 |
| 绘制单位 | 青岛理工大学环境与市政学院、青岛理工大学环境与市政学院、青岛理工大学环境与市政学院 |
| 更多格式 | 高清、无水印(增值服务) |




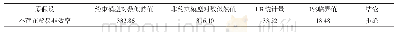

{kind=link}