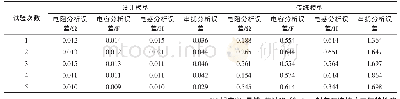
《表3 AD数据MBMA建模与Pop PK建模随机效应模型对比》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
对于IPD数据,随机效应模型的设置可参考Pop PK分析方法。对于AD数据,随机效应一般分为试验间变异(inter study variability,ISV)、组间变异(inter arm variability,IAV)和残差变异(residual variability,RUV),可以参照Pop PK中的个体间变异(inter individual variability,IIV)、周期间变异(inter occasion variability,IOV)和RUV进行设定(表3)[48]。另外,由于汇总数据中每个试验组的不同时间点测量值来自同一患者群体,通常认为它们之间存在相关性,需要在残差变异中进行相关设定,在NON-MEM软件中可以通过L2 (level two)数据列进行相关性残差变异的设置,具体的模型代码可参见相关文献[49]。
| 图表编号 | XD00199610500 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.11.26 |
| 作者 | 李禄金、丁俊杰、刘东阳、王曦培、邓晨辉、季双敏、陈文君、马广立、王鲲、盛玉成、许羚、裴奇、陈渊成、陈锐、史军、李改玲、王亚宁、王玉珠、谢海棠、周田彦、方翼、张菁、焦正、胡蓓、郑青山 |
| 绘制单位 | 上海中医药大学 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}