《表1 部分特征项权重比较》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
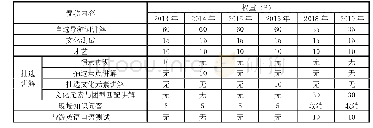
社交文本的特性为文本长度较短,但总体的词汇量较大,在不同的时间段会派生出许多新的词汇,训练集中出现的词汇一般遵循Zipf定律,即只有少数词汇被经常使用[11]。大量词汇在训练集中出现的次数很少甚至只出现1次,这些词汇被称为稀有词汇,它们对分类的特征选择贡献度很低。因此,在构建决策表时,可以把每个特征项作为决策表中的一个属性看待,计算得出的属性权重即特征项权重。本研究在计算权重时,过滤了出现次数少于或等于3次的词汇,过滤后再根据训练集D={d1,d2,…,dn}得到所有社交文本的特征项集合T={t1,t2,…,tm},以每条文本在相应特征项的取值计算该特征项的权重,计算权重采用TF-IDF权重计算方法。表1给出了两条社交文本中部分特征项的权重值,可以看出:“Mobile”类别中编号为“1141”的社交文本包含了“魅族”“诺基亚”这两种类别区分度较高的特征项,其权重值相对较大;而特征项“微博”“转发”这两种类别区分度较低的特征项,其权重值相对较小。
| 图表编号 | XD00194445800 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.12.25 |
| 作者 | 曹守富、蒋慧平、谭阳 |
| 绘制单位 | 湖南广播电视大学教育信息技术中心、湖南网络工程职业学院网络技术学院、湖南网络工程职业学院网络技术学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}