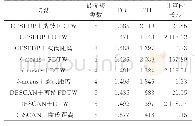
《表3 不同负荷曲线聚类算法性能指标及计算时长》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《基于剪枝策略和密度峰值聚类的行业典型负荷曲线辨识》
分别采用本文算法、自适应k-means算法[28]和基于密度的噪声应用空间聚类(density-based spatial clustering of application with noise,DBSCAN)算法[29]对金属加工机械制造行业负荷样本集进行聚类分析和对比,并采用DB和CalinskiHarabas(CH)指标[4]衡量不同负荷相似性量度距离和聚类算法对负荷曲线分类的效果。DB指数是衡量聚类性能常见指标,为分类簇内的平均距离和簇间的最小距离之比,其值越小越好;CH指标通过簇内离差矩阵量度紧密度,簇间离差矩阵量度分离度,其值越大,表明簇内样本越紧密,簇间区别越大,则聚类效果越好。DB和CH指标值的表达式见附录C(附录),其中CH指标基于用电负荷的5个形态特征指标,用于衡量聚类算法对不同需求响应潜力的负荷分类效果[4]。不同算法的最优聚类数(由DB确定的)及其聚类结果的性能指标和计算时长如表3所示,其中k-means聚类不是密度聚类,因此采用未剪枝的FDTW距离。
| 图表编号 | XD00192199800 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2021.02.25 |
| 作者 | 金伟超、张旭、刘晟源、黄荣国、潘柏良、林振智 |
| 绘制单位 | 浙江大学电气工程学院、国网浙江省电力有限公司营销部、浙江大学电气工程学院、国网浙江省电力有限公司营销服务中心、浙江华云信息科技有限公司、浙江大学电气工程学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}