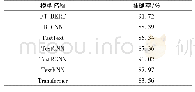
《表4 各模型在测试集上的准确率》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
为验证文本算法的有效性,在非均衡数据集基础上,使用航天科技开源情报数据微调模型,本文简称FT_BERT模型,并将该模型与目前部分主流语言模型在航天科技开源情报文本分类任务中的表现做了对比。在实验过程中为各模型设置了相同的基本超参数:随机失活率为0.5,Epoch为20,学习率为e-3,最大文本长度为256。各模型在测试集上的准确率如表4所示。
| 图表编号 | XD00189137000 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2021.02.01 |
| 作者 | 孔凡芃、刘旭红、刘秀磊、李晗 |
| 绘制单位 | 北京信息科技大学网络文化与数字传播北京市重点实验室、北京信息科技大学数据与科学情报分析实验室、北京信息科技大学网络文化与数字传播北京市重点实验室、北京大学北大方正集团有限公司数字出版技术国家重点实验室、北京信息科技大学网络文化与数字传播北京市重点实验室、北京信息科技大学数据与科学情报分析实验室、北京信息科技大学网络文化与数字传播北京市重点实验室、北京信息科技大学数据与科学情报分析实验室 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}