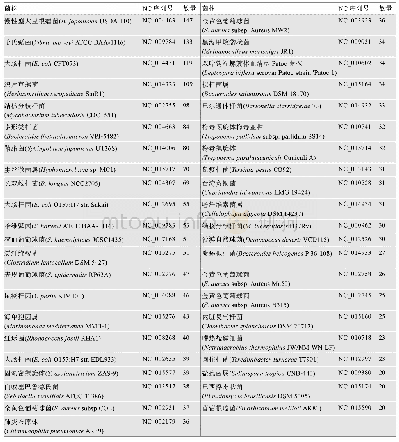
《表1 识别出过度注释的ORFs多于20的菌株基因组的信息》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《基于序列相似性和Z曲线方法重注释原核生物蛋白编码基因》
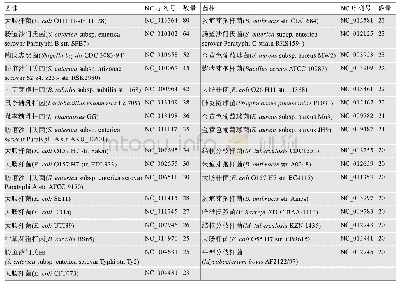
由于计算方法本身的偏差,本研究使用实验数据进一步确定这些序列是否为非蛋白编码序列。当且仅当这些序列在公共数据库中查询不到表达数据,才认为它们确实不具有编码功能。研究查询了GEO等数据库并最终确定177个基因组中共3092个ORFs为过度注释为基因的序列(附表5)。需要重点提及的是其中43个基因组有20个以上的假定ORFs被识别为这类序列(表1)。
| 图表编号 | XD00176372300 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.07.01 |
| 作者 | 刘硕、曾志、曾凡才、杜萌泽 |
| 绘制单位 | 电子科技大学生命科学与技术学院、电子科技大学生命科学与技术学院、西南医科大学基础医学院分子生物与生物化学教研室、西南医科大学基础医学院分子生物与生物化学教研室 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}