《表4 筛选后的特征汇总表》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
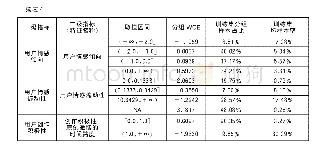
首先,通过分箱对变量做离散化处理,本文选择卡方分箱方法。分箱后,连续变量被划入对应取值区间,同时被赋予对应的证据权重WOE值,WOE是对原始自变量编码的一种方式。在后续逻辑回归建模过程中,自变量将以WOE值表示。分箱后,选择基于IV值(证据权重)进行筛选的方式对表1提出的特征进行选择。IV值表征每个指标对应的信息价值,IV值越高,自变量对目标的影响越大,一般需要保留IV值高于0.02的特征。通过筛选的特征如表4所示。此外,表4还提供了通过筛选的各个特征的取值区间、各取值区间对应的WOE值及代表性分析结果。训练集分组样本占比用来描绘训练样本落入各个取值区间的比例。训练集坏样本率用来刻画训练集中的坏样本(高危人群)落入各个取值区间的比例,用以评估坏样本在各个取值区间出现的概率。从8065名用户中随机抽取70%的用户数据作为训练集,剩余30%的用户数据作为测试集。将表4中的特征作为训练模型的特征输入得到如表5所示的逻辑回归指标系数。根据表5中的逻辑回归指标系数,建立高危人群预测模型,如等式(11)所示。
| 图表编号 | XD00175576900 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.01.26 |
| 作者 | 吴林、安璐、孙冉 |
| 绘制单位 | 武汉大学信息资源研究中心、武汉大学信息管理学院、武汉大学信息管理学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}