《表3 不同模型的实验结果对比》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
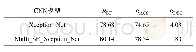
本文设计并实现了安全类文章多文本分类系统,主要包含信息采集模块和信息分类模块,首先通过信息采集模块对安全类网站进行大量的信息采集,将采集到的文本数据存入数据库,然后通过信息分类模块对存入数据库中的文本进行了预处理及文本表示,具体包括数据清洗、文本分词、文本表示等,将文本表示后得到的词向量分别输入CNN模型、LSTM模型和CNN-LSTM模型这3个文本分类模型进行多文本分类实验。实验结果表明,CNN-LSTM混合模型的准确率和F1值分别达到91.99%和88.02%,均优于CNN和LSTM模型。
| 图表编号 | XD00174135700 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.07.10 |
| 作者 | 吴习沫、朱广宇、张雷 |
| 绘制单位 | 华北计算机系统工程研究所、华北计算机系统工程研究所、华北计算机系统工程研究所 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}