《表6 文本检测方法在Total-Text和CTW-1500上的性能对比》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
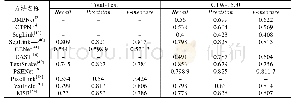
(2)文本检测方法在曲线文本检测数据集Total-Text和CTW-1500上的性能见表6.目前,很多文本检测模型将文本区域的线性特征作为先验条件检测水平或者倾斜的文本框,导致无法较好的检测曲线文本,其中,DMPNet[31]、CTPN[14]、SegLink[15]、CENet[41]和PixelLink[18]在数据集Total-text上的F-measure不超过0.6,在数据集CTW-1500上的F-measure最高只有0.604.SegLink++[40]的改进,使其在Total-Text数据集上的F-measure达到了0.815,在数据集CTW-1500上的F-measure相较于SegLink[15]提高了0.405,仅略次于TextField[20].TextSnake[49]采用不同大小和连接角度的圆盘表示文本区域,从而能够检测直线和曲线文本,在数据集TotalText和CTW-1500上的F-measure分别达到了0.784和0.756.PSENet[19]凭借其简单独特的多级文本区域分类预测,在数据集CWT-1500上取得了极佳的性能,其F-measure达到了0.811 7.TextField[20]和MSR[54]基于边界特征检测的方法在数据集Total-Text和CTW-1500上的准确率都超过了0.8,其中,TextField[20]使用方向向量场检测方式在数据集上Total-Text和CTW-1500上分别取得了0.806和0.814的F-measure;而MSR[54]方法的检测准确率则优于其他方法,在数据集Total-Text上的准确率相对TextField[20]提高了0.04.
| 图表编号 | XD00168931900 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.05.01 |
| 作者 | 王建新、王子亚、田萱 |
| 绘制单位 | 北京林业大学信息学院、国家林业草原林业智能信息处理工程技术研究中心(北京林业大学)、北京林业大学信息学院、国家林业草原林业智能信息处理工程技术研究中心(北京林业大学)、北京林业大学信息学院、国家林业草原林业智能信息处理工程技术研究中心(北京林业大学) |
| 更多格式 | 高清、无水印(增值服务) |






{kind=link}