《表9 Derby数据集结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
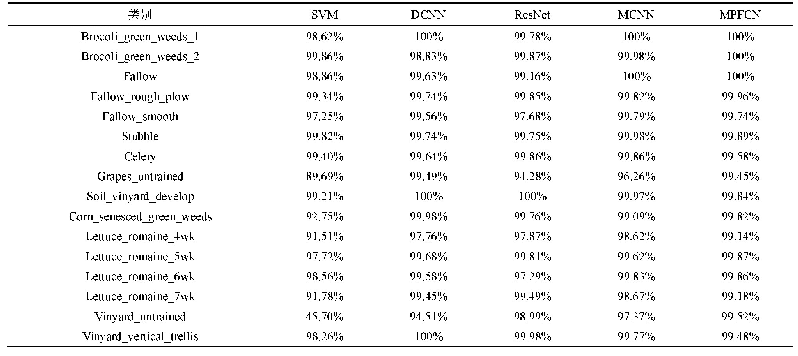
从表7~表10我们可以发现,在4个小规模数据集中,Nnsbr:Nsbr比例越小(即不均衡程度越低),性能指标Recall的取值越大;但是Precision指标的取值却恰恰相反,并最终造成F1-score指标的取值也呈减小趋势.与原始数据集(未进行采样)执行结果(即表5)相比,“欠采样”方法对4个小规模数据集的性能贡献非常有限,只有在数据集Wicket上对F1-score有所提高.对于大规模数据集OpenStack,对比表11和表5(最后一行)数据可以发现,所采用的“过采样”方法可以明显提高F1-score指标取值,尤其在模型TextCNN中,F1-score指标的最大取值可以从原始数据集中的0.410提高到0.681(复制2倍正样本情况下),即提高了66.10%;但是在正样本复制3倍的情况下,F1-score指标的取值则呈下降趋势.此外,在4个小规模数据集中,“欠采样”方法对TextCNN和Attention+TextRNN模型的影响类似,所得到的性能指标值非常接近(例如数据集Ambari中,在Nnsbr:Nsbr=10:1的情况下,模型TextCNN和Attention+TextRNN所得的F1-score值都为0.611).而在大规模数据集OpenStack中,对训练样本进行“过采样”处理后,模型TextCNN的整体表现要优于Attention+TextRNN.
| 图表编号 | XD00168928300 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.05.01 |
| 作者 | 郑炜、陈军正、吴潇雪、陈翔、夏鑫 |
| 绘制单位 | 西北工业大学软件学院、空天地海一体化大数据应用技术国家工程实验室(西北工业大学)、大数据存储与管理工业和信息化部重点实验室(西北工业大学)、西北工业大学软件学院、西北工业大学自动化学院、西北工业大学软件学院、南通大学信息科学技术学院、Faculty of Information Technology, Monash University |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}