《表9 不同数据集上-各方案实验结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
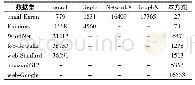
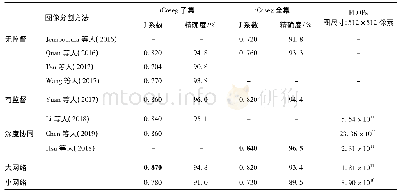
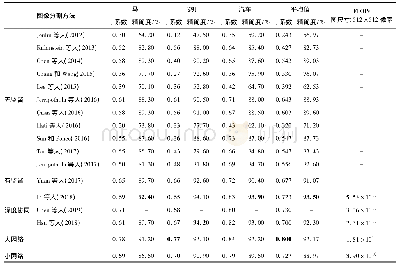
各算法在均衡数据集上的性能指标均显著优于原始非均衡数据集。Coo_score+Ind_index方案的F1提升幅度最高,未引入关联词时,F1从0.576升至0.705;引入关联词后,F1从0.590升至0.750。分析原因,基于指标的关系推断本质上利用的是词语和特征类的共现率,因而受到类别样本量的影响更显著。类别样本量不均衡的情况下,词项与样本量少的类别的共现得分偏低,词项类别预测倾向于样本量多的类别,影响了算法的整体表现。信息增益分类法受语料均衡性的影响相对较小,但均衡语料上的表现也优于非均衡语料。整体比较,均衡语料上,引入关联词的Coo_score+Ind_index方案综合表现最优(P=0.754,R=0.759,F1=0.750),结果如表9所示。
| 图表编号 | XD00139938300 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.01.25 |
| 作者 | 聂卉、何欢 |
| 绘制单位 | 中山大学资讯管理学院、中山大学资讯管理学院 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}