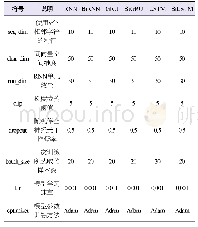
《表1 算法参数设置:基于连续频谱最小值跟踪的语音增强算法》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
实验语音来源于TIMIT数据库,一半男声一半女声,采样频率为16kHz,采样精度为16bit。噪声来源于Noisex92噪声数据库,其中包括babble、factory、white、street noise、cafeteria等噪声类型,按照[-5,0,-5]dB的信噪比对语音进行叠加不同种类的噪声。语音分析中设定帧长为320个样点,帧移为160个样点。为了增加本文提出的算法与原算法的可比性,将与最小值跟踪方法无关的参数值设置为原算法[5]中的值,具体设置如表1所示。
| 图表编号 | XD0016873500 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2018.07.01 |
| 作者 | 邵虹、王杰 |
| 绘制单位 | 沈阳工业大学信息科学与工程学院、沈阳工业大学信息科学与工程学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}